环境
都说python是很棒的语言,入门学习曲线可以说是相当亲民,但各种环境的“崎岖”让人望而却步,我到底应该用pip呢还是anaconda这样的问题让人挠头,见图便知。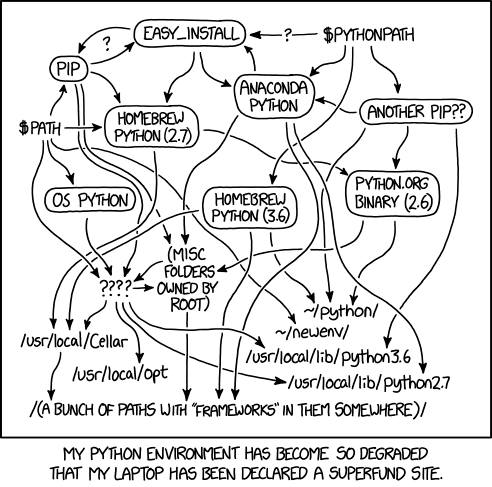
我的需求
easybuild依赖于python,简单介绍一下用easybuild:它属于Modules上一级的工具,可以(自动搜寻依赖关系)安装各种版本的python,安装相应的python库,配置相应的清晰干净的python环境,尤其在多用户高性能计算机群上广泛使用。我需要管理手头多个版本的OpenFOAM和与它们依赖的库(其实主要用到的也就mpi和scotch)。用户体验:当你的工作环境很单一不用Modules没问题,不过一旦复杂度上去了,用Modules工具可以做到事半功倍,”模块化的环境”不仅让工作环境清爽整洁、条理清楚,还可以不费劲地将自己熟悉的整个工作环境在另一台机器上复现出来。我手头与python依赖的环境有:
- Linux CentOS 系统自带 /usr/bin/python
- easybuild (基于1的安装)
- /usr/bin/ipython
- /usr/bin/pip
- anaconda
我要使用easybuild安装的module的时候用这个alias:1
2
3
4alias Easybuild='EASYBUILD_PREFIX=$HOME/.local/easybuild; \
module use $EASYBUILD_PREFIX/modules/all; \
module load EasyBuild; \
EASYBUILD_MODULES_TOOL=EnvironmentModules'
根据我的设置,默认不加载easybuild的环境。1
2
3
4
5$ echo $PYTHONPATH
$ Easybuild
$ echo $PYTHONPATH
/home/hluo/.local/easybuild/software/EasyBuild/3.2.1/lib/python2.7/site-packages
看到上图里面右上角那个至少有三个箭头朝外的环境变量了吗?就是它。
而anaconda有它自己一套的环境变量:
1 | $ Anaconda # 加载anaconda环境 |
为啥两个库存放的地方不同?按理说这是pip安装的目录(见下文),我肯定之前干了什么然后失忆了,促成了此“姻缘”。。。总之我在尝试安装h5py的时候遇到了各种问题,最终因为盘根错节根本厘不清!想搞清楚?重装吧。其实每次重新安装都有“做得更好”的可能,前提是厘清楚,然后养成好的习惯在使用的时候用哪一个就哪一个,切忌同时使用pip和anaconda。
一个程序就做一件事情,然后把它做好,身边的计算机牛人们说过的话,受用了。
pip
实验室哥们推荐我单用pip,他给我的使用建议:
安装scipy,pip install --user scipy,所安装的包就在$HOME/.local/lib/python2.7/site-packages
更新scipy,pip install scipy --user -U,所安装的包就在$HOME/.local/lib/python2.7/site-packages
移除所安装的包直接删除对应位置的文件即可,如果想用另一个版本直接将当前的包删除即可,这样干净整洁不容易出错,此例中rm -rf $HOME/.local/lib/python2.7/site-packages/scipy*
查看包的版本
1 | $ pip install scipy== |
如果是python3的库,那么就改用pip3,库函数就会放在$HOME/.local/lib/python3.4/site-packages(这里是3.4)
安装特例
需要指出的是一般python包按照以上傻瓜安装就行,并不需要操心这么多,这里仅为一个特例。
h5py的安装需要用到devel包(for developper 或者叫 no-binary 包),因为基于h5py的特性需要基于已有的mpi和hdf5重新编译,比如安装的时候报错Python.H not found,那就说明python包里面该有*.H的地方没有源文件,也许安装的不是开发者安装包(仅仅是pre-compiled后的库函数,类似于apt-get install安装时从源上拷贝到本地的packages);当然另一种可能的情况是给的头文件寻找路径不对。
小结一下,如果报错找不到mpi.h或者hdf5.h,那么就是环境中找不到mpi或hdf5包里的头文件,也对应前面两种可能:包里面不包含*.H或者搜索路径不对。这种时候,意味着h5py需要在本地重新编译。
这里说起来有点绕,这是因为h5py是python对hdf5库的一个wrapper,也就是基于用C或者C++的hdf5库的接口重新包装的结果,因而需要保证在当前环境中hdf5库已经配置完整(包括CPATH指定头文件的路径,LD_LIBRARY_PATH指定*.so库的搜索路径),别忘了hdf5依赖于mpi,那么mpi也应该完成配置。这样才能保证重新编译的基本要求,在python里面no-binary安装对应:
1 | $ pip install --user h5py # 预编译 |
anaconda
anaconda也可以安装在自己$HOME下且包很全,有个conda命令来管理包的历史、更新、安装、卸载。我在初期就用anaconda,试图用conda安装h5py失败了(安装h5py的动机源自一篇关于OpenFOAM湍流进口条件的学士论文,可惜这个人写的库只适用于structured rectilinear grid,也就是进口得是方形,圆管就不行了。对于我来说,直接用用不上,但eddylicious库的编写里得更多的是面向过程,加上只有一个轴的方向y是边界层,蛮好读懂;另一方面他改写了timeVaryingMappedFixedValue,把输出格式改成了HDF5,按照要求编译:要注意Make/options里面通过HDF5_DIR而不是CPATH和LD_LIBRARY_PATH来找,且在环境中设置不够,需要写入到Make/options里面HDF5_DIR=$HOME/.local/easybuild/software/HDF5/1.8.17-foss-2016a,这里的HDF5用easybuild安装,跟使用的OpenFOAM/2.3.1-foss-2016a匹配),就h5py来说,pip网上的资料还是多些。
IDE
我在windows和linux下也都有anaconda,主要用在包里的spyder,可以实时查看数组变量(函数内部的变量在IDE里面查看不了,因为没有暴露在当前执行脚本的环境中),这在python学习初期很有用,在初期学习中可以有意识地不写函数,这样所有的变量都在可追溯的Variable explorer里面便于实时查看。想要查看某变量的类型,在里面集成的ipython console通过type(variable)输出即可。
我选spyder的主要原因:
- 用matplotlib画图的时候就在ipython console即时输出图片,避免另弹出画图的新窗口+手动关闭窗口,看到图片就可以调整legend的位置还有字体大小什么的,很直观;如果要拷贝图片另存为png格式直接右键
save image as就可以,所见即所得(为何这样说?如果legend在图片box外面,savefig不会将legend包括进去,也就说savefig最终不会包含box外的legend)。 - 库函数自动补全
- 注释和去注释方便,缩进和去缩进方便,高亮易辨识
- 鼠标点击函数,在不同的库之间跳转
福利: spyder -> File -> Print to File (PDF) 有语法高亮
局限: 上面1提到的legend在外的情况可能会有点麻烦;在3d plot里面有些图(比如3D云图)是可以鼠标拖着旋转的,但在spyder里面就是个静止的图(可能原因在于就其本源可能还不如货真价实的ipython console);因此animation当然也在spyder里面看不了,这个时候就都得回到无IDE下的python解释器环境
基本数据类型
Sequence Types — str, unicode, list, tuple, bytearray, buffer, xrange
- str : string, written in single or double quotes
- unicode : unicode string, much like string
- list : constructed by square brackets, its element seperated by comma
- tuple : constructed by the comma operator (not within square brackets), with or without enclosing parentheses, but an empty tuple must have the enclosing parentheses, such as a, b, c or (). A single item tuple must have a trailing comma, such as (d,).
- bytearray : created with the built-in function bytearray()
- buffer : Buffer objects are not directly supported by Python syntax, but can be created by calling the built-in function buffer()
- xrange : similar to buffers in that there is no specific syntax to create them, but they are created using the xrange() function
Operators on list1
2
3
4
5
6myList = ["The", "earth", "revolves", "around", "sun"] # initialize a list with double quotes
myList
['The', 'earth', 'revolves', 'around', 'sun'] # output are single quoted
myList = myList + ["sure"] # need a list to perform operator+ on list objects
myList
['The', 'earth', 'revolves', 'around', 'sun', 'sure'] # list + list = list
Sequence Types – dict
A mapping object maps hashable values to arbitrary objects. Mappings are mutable objects (in c++ there are also mutable objects, what are they?). There is currently only one standard mapping type, the dictionary.
Dictionaries can be created by placing a comma-separated list of key: value pairs within braces, for example: {‘jack’: 4098, ‘sjoerd’: 4127} or {4098: ‘jack’, 4127: ‘sjoerd’}, or by the dict constructor.
以上是抄写,这里是个人使用心得:
list里面可以放不同类型的变量,很有用;
tuple可以作为函数return多个值的时候的选项例如
fig, ax = plt.subplots(),当然dictionary也可以;- 我在OpenFOAM后处理脚本里面用到dict,因为一个dictionary就可以包含算例的绝对路径、后处理时间区间,后处理数据shape…更重要的是在程序读取并处理数据时,主程序里
暴露出从key到value的过程,比如如果我画平均值就取名为mean,如果画均方根就取名为rms,这样后处理程序可读性会大大提高;numpy里面array当然用得很多,list可以转化为array
库的使用
python强大的地方当然是有各种很棒的库的支持(numpy, scipy, matplotlib等),使用库用关键字import就行。如何查询所用库的路径?进入ipython1
2
3
4
5
6
7
8
9
10In [1]: import numpy as np
In [2]: np.__ # 自动补全
np.__
np.__NUMPY_SETUP__ np.__delattr__ np.__getattribute__ np.__new__ np.__repr__ np.__version__
np.__all__ np.__dict__ np.__git_revision__ np.__package__ np.__setattr__
np.__builtins__ np.__doc__ np.__hash__ np.__path__ np.__sizeof__
np.__class__ np.__file__ np.__init__ np.__reduce__ np.__str__
np.__config__ np.__format__ np.__name__ np.__reduce_ex__ np.__subclasshook__
In [2]: np.__path__
Out[2]: ['/home/hluo/.local/lib/python2.7/site-packages/numpy'] # 可以看到输出的是一个list,里面路径变量是str
自定义库
自定义库也很简单,写了一个脚本叫Dai_thesis.py,里面有个函数叫Fig4p8a,那么在主程序(同一目录下)只需import Dai_thesis,然后就可以Dai_thesis.Fig4p8a(),在执行主程序的时候Dai_thesis.pyc将会自动生成,这是个二进制文件,表明Dai_thesis.py以库的形式被使用,这样就使用了Dai_theis这篇论文里面Fig4.8(a)里面的数据。当然库的使用也有嵌套,例如在上述基础上加一个层级:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99# 高层级的库 reference_database.py : 我画图的时候作为对照的的数据来源汇总:杂志文章、博士论文、解析表达式
import Niewstadt_article_1995
import Dai_thesis
import analytic_functions
import Eggels_thesis
import Eggels_article_1994
# 低一个层级的 Dai_thesis.py : 功用是去特定的地方读特定的文件,返回numpy array组成的一个tuple
import numpy as np
def Fig4p8a(fluid):
string='/home/hluo/Pictures/Dai_T/meanProfile_velocity/XEqM4_debitMin/profile_XEqM4_debitMin.csv'
data=np.genfromtxt(string,skip_header=1,delimiter=',')
switcher={
'EAU':1, # 选择流体类型
'PAA':2,
'XG':3
}
x = data[:,0]
y = data[:,switcher[fluid]]
return x, y
def Fig4p9a(fluid):
string='/home/hluo/Pictures/Dai_T/meanProfile_velocity/XEqP12_debitMin/profile_XEqP12_debitMin.csv'
data=np.genfromtxt(string,skip_header=1,delimiter=',')
switcher={
'EAU':1,
'PAA':2,
'XG':3
}
x = data[:,0]
y = data[:,switcher[fluid]]
return x, y
# parameters_T_RES1d_MethodMapped_subMethod_NearestFace.py : 用dict存储一个OpenFOAM算例后处理里的复合数据类型
# physical parameters
physics={
'R':0.004,
'nu':1.0e-6,
'uTau':0.0473
}
# output of sample utility
sampling={
'raw_sample_size':160,
# 'dataShape':(199,4) # uniform
# 'dataShape':(188,4) # face 3
'dataShape':(195,4) # face 2
# 'dataShape':(195,4) # face 1
# 这里展示了这个后处理过程的复杂性:dataShape有多个值
# 因为OpenFOAM sample sets操作后的数组用不同mode输出的数据长度不同
# 例如: uniform 和 face 两个mode下输出的长度不同,在同一mode下不同的地方进行sample操作也可能得(对于
# 复杂的几何外形的算例,网格在空间不均匀,换个sample的位置,几乎一定会变)的不同长度的数据,例如这里的
# face 1,2,3
# 为何要确定长度?因为如果做空间统计(这个例子是时间,只要网格不变,sets不变那数据长度就不变,因为取
# 样的labelList不变),比如在周期条件的圆管流动里,里面沿着半径方向取一系列数学上有对称性的sets,然后
# 想求对于sets的平均(即空间平均),每个sets在这里对应一个数据文件。这时候即使是相当规则的网格(butterfly
# 分成5块),我的测试结果是:这一系列看起来数学上完全对称的sets有时候也会出现个别的特例(要么输出数据
# 长度为0,要么输出数据跟大部分的shape不同,OpenFOAM当然不会报错警告你,所以我自己建立了一个检查机制,
# 这样呢就需要一个目标shape和读取实际数据shape的对照的过程,这样每次后处理我就知道是否有exception。
# 于是在这里,通过这样一个dictionary完成了参数parameters['sampling']['dataShape']的传递)
}
# data entry parameters
dataEntry={
'startTime':5.5, # KinecticEnergy stationary
'endTime':7.2, 'chunkStep':50,
'NbOfFiles':171,
'path':"/store/caseByGeometry/T/new-mesh/pointwise/postProcessing/1d_mapped_NearestFace",
}
parameters={
'physics':physics,
'sampling':sampling,
'dataEntry':dataEntry,
}
最后看看主程序,rdb.Dai_thesis.Fig4p9a()完成了对两个自定义库的嵌套,可读性强;函数传入一个dict比传入长串多个参数可读性强,比如tsR.pre_check(ps_map.parameters,...);在主程序中显式操作数据(无量纲化,坐标轴变换),有迹可循。可读性是强了,可维护性呢?
基于这个主程序,如果要加上另一个算例(例如空间分辨率不同)的结果画在同一个图中,该怎么做呢?编辑另一个算例相应的dict(路径,时间区间等),然后在主程序开头处import即可(注意,实际上编辑的不是dict,而是库,我这里通过库的形式传入dict);如果要对同一个算例,画出在两个时间区间的统计结果,怎么办?我的做法是深度拷贝ps_map.parameters这个dict,在主程序里面显式地修改时间区间(为什么是显式的?因为key是’startTime’,’endTime’,改的变量是什么对于使用者来说很直观),这样通过这个修改后的dict传入参数,做同样的pre_check和process两行操作就可以,主程序仍旧保持着相当一致的格式(较为固定的两行操作)。如果要做一个以上两个变种的融合不外乎多几个两行操作,易于维护。
加上pre_check会对读入数据是否valid进行判断,因此也易于debug。
用spyder来操作,实时得图,实时跳转至库文件编辑,实时在主程序调整画图的参数。
1 |
|
小结:这里主要借我自己在OpenFOAM中后处理的用法(库,库的嵌套,字典,深度拷贝,函数返回值可以是多个[tuple或者dict])来介绍python的基本数据类型,会在另一篇博客中给出针对sample这个重要的OpenFOAM utility的全部流程。
matplotlib
basics
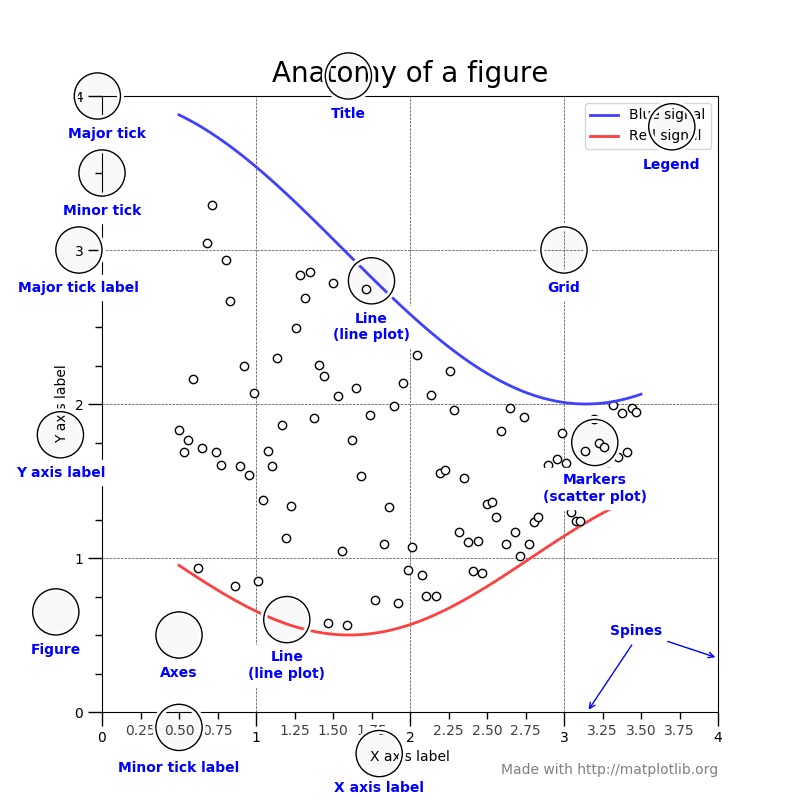
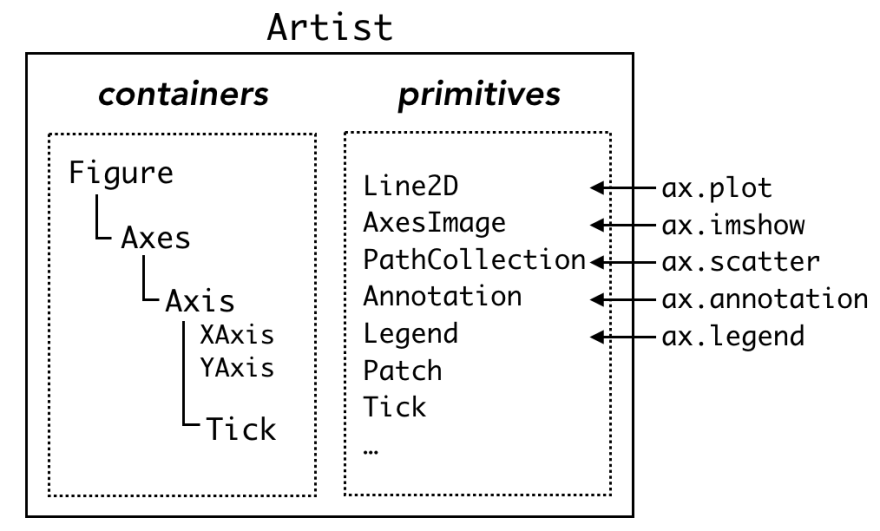
关于matplotlib里面Figure, Axes, Axis, Tick的层级关系,这个博客很好
通过传递ax来画出caseList里面的所有中间图像,利用cut来区分取实际数据的哪个slice,用ax_principle来画最终的图像
1 | # -*- coding: utf-8 -*- |
backend
在非图形化界面(非anacoda+spyder)情况下,有可能遇到ImportError: No module named Tkinter而卡住在backend上画不出任何图,需要在文件头加上
1 | import matplotlib |
这样至少可以savefig成功
rcParams
1 | # 这段代码修改的是全局变量,但是 |
图片尺寸大小
1 | fig, ax = plt.subplots(figsize=(16,10)) # 16 inches * 10 inches |
add image to a plot
1 | fig, ax = plt.subplots() |
doctest库
这个库挺酷,不过不知道用处大不大,一言以蔽之:这是一个自我检测跨行注释里面内容是否通过测试的库。
1 | #!/usr/bin/env python2 |
测试python demo1.py没有任何输出;如果加上-v
1 | $ python demo1.py -v |
不过这里要注意的是貌似python自带一个Interval的库,所以…有些干扰:比如这里只有__lt__和__eq__,没有__gt__,但可以有操作:
1 | a > b |
总结一下,这个库可以用于检测函数的基本功能是否完好。但需要满足前提条件:必须是三个引号那种注释,注释得是>>>这种interactive(也就是ipython)里面的格式且不能随意换行;可以在函数里面单独加入一个comment block;但是在头上加入一个随意其他的换行comment好像有可能导致功能失效
Debug
缩进
文本编辑器 vim > gedit 主要小心空格和tab混用,很难找出为啥来1
2
3
4
5$ python -t script.py
# This will warn you if you have mixed tabs and spaces
$ cat -A script.py
# On *nix systems, you can see where the tabs
spyder
有次遇到了TypeError: 'str' object is not callable,找了半天都没有头绪,结果重启spyder就好了。说明有些错,真不简单,试试重启大法。
python提交算例到机群
而你又没有pySlurm的时候…..
实用手册
iterable
iterable顾名思义就是“能堪循环者”,python里面循环可以有简单写法for item in some_list:,这样可以省去指明循环指标变量i。不专业的(我)使用的时候有时候还是想要加上i,但似乎不是所有的iterable都可以加i,例如f = open(fileName,'r')这里返回值f是type file,它就不能用i来引用,想要对它循环输出行号,我没有成功.[待贴代码验证]
当iterable在循环中被改变(比如list.remove()),要特别注意!!可能会直接跳出循环,因为iterable被改变了
str are immutable
python里面str可以slice,但不能被修改,string.replace也只是对其拷贝进行的replace操作.参考stackoverflow